可执行文件 doxygen 是解析源代码并生成文档的主程序。有关更详细的用法信息,请参阅Doxygen 用法部分。
可选地,可以使用可执行文件 doxywizard,它是用于编辑 Doxygen 使用的配置文件以及在图形环境中运行 Doxygen 的图形前端。对于 macOS,点击 Doxygen 应用程序图标即可启动 Doxywizard。
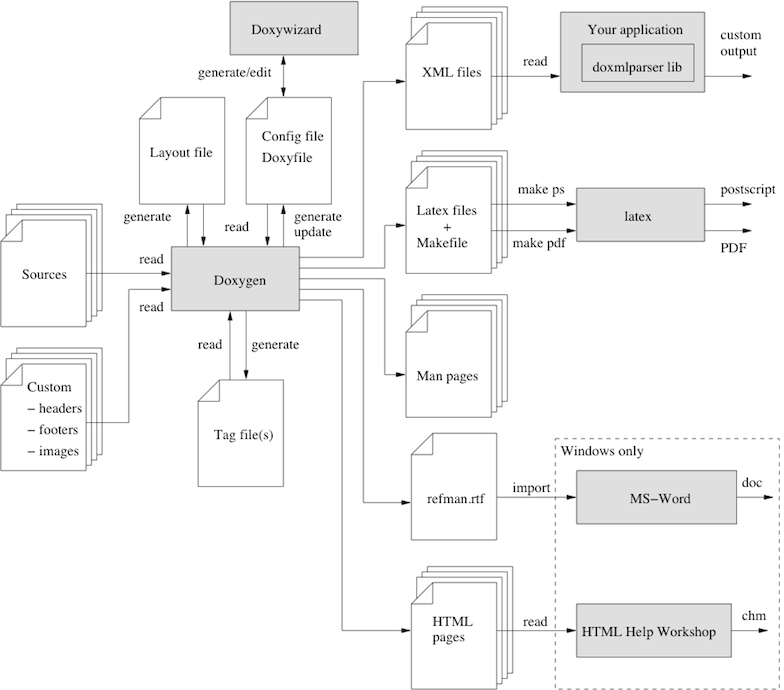
下图显示了工具之间的关系以及它们之间的信息流(它看起来很复杂,但这仅仅是因为它试图做到完整)
首先,确保您的编程/硬件描述语言有很大可能被 Doxygen 识别。Doxygen 默认支持以下编程语言:C、C++、Lex、C#、Objective-C、IDL、Java、PHP、Python、Fortran 和 D。Doxygen 默认也支持硬件描述语言 VHDL。可以配置某些文件类型扩展名以使用特定的解析器:有关详细信息,请参阅配置/扩展映射。此外,通过使用预处理器程序,可以支持完全不同的语言:有关详细信息,请参阅帮助页面。
Doxygen 使用配置文件来确定其所有设置。每个项目都应该有自己的配置文件。一个项目可以由单个源文件组成,也可以是递归扫描的整个源树。
为了简化配置文件的创建,Doxygen 可以为您创建一个模板配置文件。为此,请从命令行调用 doxygen 并带上 -g 选项
doxygen -g <config-file>
其中 Doxyfile 的文件。如果已存在名为 -(即减号)作为文件名,Doxygen 将尝试从标准输入 (stdin) 读取配置文件,这对于脚本编写很有用。
配置文件的格式类似于(简单)Makefile。它由许多形式为
TAGNAME = VALUE 或
TAGNAME = VALUE1 VALUE2 ...
的赋值(标签)组成。您可能可以将生成的模板配置文件中大多数标签的值保留为默认值。有关配置文件的更多详细信息,请参阅配置部分。
如果您不想用文本编辑器编辑配置文件,您应该查看Doxywizard,它是一个 GUI 前端,可以创建、读取和写入 Doxygen 配置文件,并允许通过对话框输入配置选项。
对于由几个 C 和/或 C++ 源文件和头文件组成的小项目,您可以将 INPUT 标签留空,Doxygen 将在当前目录中搜索源文件。
如果您有一个由源目录或树组成的较大项目,您应该将根目录或目录分配给 INPUT 标签,并向 FILE_PATTERNS 标签添加一个或多个文件模式(例如 *.cpp *.h)。只有与其中一个模式匹配的文件才会被解析(如果省略模式,则使用 Doxygen 支持的文件类型的典型模式列表)。对于源树的递归解析,您必须将 RECURSIVE 标签设置为 YES。为了进一步微调解析文件列表,可以使用 EXCLUDE 和 EXCLUDE_PATTERNS 标签。例如,要从源树中省略所有 test 目录,可以使用
EXCLUDE_PATTERNS = */test/*
Doxygen 通过查看文件的扩展名来确定如何解析文件,使用下表
| 扩展名 | 语言 | 扩展名 | 语言 | 扩展名 | 语言 |
|---|---|---|---|---|---|
| .dox | C / C++ | .HH | C / C++ | .py | Python |
| .doc | C / C++ | .hxx | C / C++ | .pyw | Python |
| .c | C / C++ | .hpp | C / C++ | .f | Fortran |
| .cc | C / C++ | .h++ | C / C++ | .for | Fortran |
| .cxx | C / C++ | .mm | C / C++ | .f90 | Fortran |
| .cpp | C / C++ | .txt | C / C++ | .f95 | Fortran |
| .c++ | C / C++ | .idl | IDL | .f03 | Fortran |
| .cppm | C / C++ | .ddl | IDL | .f08 | Fortran |
| .ccm | C / C++ | .odl | IDL | .f18 | Fortran |
| .cxxm | C / C++ | .java | Java | .vhd | VHDL |
| .c++m | C / C++ | .cs | C# | .vhdl | VHDL |
| .ii | C / C++ | .d | D | .ucf | VHDL |
| .ixx | C / C++ | .php | PHP | .qsf | VHDL |
| .ipp | C / C++ | .php4 | PHP | .l | Lex |
| .i++ | C / C++ | .php5 | PHP | .md | Markdown |
| .inl | C / C++ | .inc | PHP | .markdown | Markdown |
| .h | C / C++ | .phtml | PHP | .ice | Slice |
| .H | C / C++ | .m | Objective-C | ||
| .hh | C / C++ | .M | Objective-C |
请注意,上述列表可能包含比 FILE_PATTERNS 中默认设置的更多项目。
任何未解析的扩展名都可以通过将其添加到 FILE_PATTERNS 并在设置适当的 EXTENSION_MAPPING 时进行设置。
如果您开始为现有项目(因此没有任何 Doxygen 知道的文档)使用 Doxygen,您仍然可以了解其结构以及文档化结果的外观。为此,您必须将配置文件中的 EXTRACT_ALL 标签设置为 YES。然后,Doxygen 将假装您的所有源代码都已文档化。请注意,因此,只要 EXTRACT_ALL 设置为 YES,就不会生成关于未文档化成员的警告。
要分析现有软件,将(已文档化)实体与其在源文件中的定义进行交叉引用很有用。如果您将 SOURCE_BROWSER 标签设置为 YES,Doxygen 将生成此类交叉引用。它还可以通过将 INLINE_SOURCES 设置为 YES 将源代码直接包含在文档中(例如,这对于代码审查很有用)。
现在您可以输入以下内容来生成文档
doxygen <config-file>
根据您的设置,Doxygen 将在输出目录中创建 html、rtf、latex、xml、man 和/或 docbook 目录。顾名思义,这些目录包含 HTML、RTF、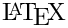 、XML、Unix Man page 和 DocBook 格式的生成文档。
、XML、Unix Man page 和 DocBook 格式的生成文档。
默认输出目录是启动 doxygen 的目录。写入输出的根目录可以使用 OUTPUT_DIRECTORY 进行更改。输出目录中特定格式的目录可以使用配置文件中的 HTML_OUTPUT、RTF_OUTPUT、LATEX_OUTPUT、XML_OUTPUT、MAN_OUTPUT 和 DOCBOOK_OUTPUT 标签进行选择。如果输出目录不存在,doxygen 将尝试为您创建它(但它不会尝试递归地创建整个路径,例如 mkdir -p)。
生成的 HTML 文档可以通过将 HTML 浏览器指向 html 目录中的 index.html 文件来查看。为了获得最佳结果,应使用支持层叠样式表 (CSS) 的浏览器(我使用 Mozilla Firefox、Google Chrome、Safari,有时也使用 IE8、IE9 和 Opera 来测试生成的输出)。
HTML 部分的某些功能(例如 GENERATE_TREEVIEW 或搜索引擎)需要支持动态 HTML 并启用 JavaScript 的浏览器。
生成的 文档必须首先由 编译器编译(我使用适用于 Linux 和 macOS 的最新 teTeX 发行版以及适用于 Windows 的 MikTex)。为了简化编译生成文档的过程,doxygen 会在 latex 目录中写入一个 Makefile(在 Windows 平台上也会生成一个 make.bat 批处理文件)。
Makefile 中的内容和目标取决于 USE_PDFLATEX 的设置。如果它被禁用(设置为 NO),那么在 latex 目录中键入 make 将生成一个名为 refman.dvi 的 dvi 文件。然后可以使用 xdvi 查看此文件,或者通过键入 make ps(这需要 dvips)将其转换为 PostScript 文件 refman.ps。
要将 2 页放在一个物理页面上,请改用 make ps_2on1。生成的 PostScript 文件可以发送到 PostScript 打印机。如果您没有 PostScript 打印机,您可以尝试使用 ghostscript 将 PostScript 转换为您的打印机能理解的格式。
如果您已安装 ghostscript 解释器,也可以转换为 PDF;只需键入 make pdf(或 make pdf_2on1)。
为了获得最佳的 PDF 输出结果,您应该将 PDF_HYPERLINKS 和 USE_PDFLATEX 标签设置为 YES。在这种情况下,Makefile 将只包含一个直接构建 refman.pdf 的目标。
Doxygen 将 RTF 输出合并到一个名为 refman.rtf 的文件中。此文件已针对导入 Microsoft Word 进行了优化。某些信息使用所谓的字段进行编码。要显示实际值,您需要全选(编辑 - 全选),然后切换字段(右键单击并从下拉菜单中选择选项)。
XML 输出由 Doxygen 收集的信息的结构化“转储”组成。每个复合(类/命名空间/文件/...)都有自己的 XML 文件,还有一个名为 index.xml 的索引文件。
还会生成一个名为 combine.xslt 的 XSLT 脚本,可用于将所有 XML 文件合并为一个文件。
Doxygen 还生成两个 XML 模式文件 index.xsd(用于索引文件)和 compound.xsd(用于复合文件)。此模式文件描述了可能的元素、它们的属性以及它们的结构方式,即它描述了 XML 文件的语法,可用于验证或控制 XSLT 脚本。
在 addon/doxmlparser 目录中,您可以找到一个解析器库,用于以增量方式读取 Doxygen 生成的 XML 输出(有关库的接口,请参阅 addon/doxmlparser/doxmparser/index.py 和 addon/doxmlparser/doxmlparser/compound.py)
生成的 man pages 可以使用 man 程序查看。您需要确保 man 目录位于 man 路径中(请参阅 MANPATH 环境变量)。请注意,man page 格式的功能有一些限制,因此某些信息(如类图、交叉引用和公式)将丢失。
Doxygen 还可以生成 DocBook 格式的输出。如何处理 DocBook 输出超出了本手册的范围。
尽管文档化源代码被列为步骤 3,但在新项目中,这当然应该是步骤 1。在这里,我假设您已经有一些代码,并且您希望 Doxygen 生成一个漂亮的文档来描述 API 以及可能的一些内部结构和一些相关的设计文档。
如果配置文件中的 EXTRACT_ALL 选项设置为 NO(默认值),那么 Doxygen 将仅为已文档化的实体生成文档。那么如何文档化这些实体呢?对于成员、类和命名空间,基本上有两种选择
在成员、类或命名空间的声明或定义之前放置一个特殊文档块。对于文件、类和命名空间成员,也允许将文档直接放置在成员之后。
有关特殊文档块的更多信息,请参阅特殊注释块部分。
将特殊文档块放置在其他位置(另一个文件或另一个位置)并在文档块中放置一个结构化命令。结构化命令将文档块链接到可以文档化的某个实体(例如成员、类、命名空间或文件)。
有关结构化命令的更多信息,请参阅其他位置的文档部分。
第一个选项的优点是您不必重复实体的名称。
文件只能使用第二个选项进行文档化,因为无法在文件之前放置文档块。当然,文件成员(函数、变量、类型定义、宏定义)不需要显式的结构化命令;只需在它们前面或后面放置一个特殊文档块即可。
特殊文档块中的文本在写入 HTML 和/或 输出文件之前进行解析。
输出的 等效项。有关所有支持的 HTML 标签的概述,请参阅HTML 命令部分。